1. Introduction
pre-trained 언어 모델(GPT2, BART)은 방대한 데이터로부터 상당한 양의 지식을 파라미터화하여 암묵적으로 저장한다. 이를 통해 언어 모델은 외부에 존재하는 메모리에 접근하지 않고도 task를 수행할 수 있다.
그러나, 학습한 모델의 메모리를 확장하거나 수정할 수 없기 때문에, hallucination을 생성할 수도 있다.
non-paramateric 메모리를 통합시켜, 지식을 직접적으로 수정하거나 확장할 수 있다. 검색을 기반으로 한 메모리의 통합은 해석 가능성도 갖는다.

RAG에서 parametric memory란 pre-trained seq2seq transformer모델을 말하며, non-parametric memory란 pre-trained retriever로 접근 가능한 위키피디아의 Dense vector index이다.
Retriever(DPR), 입력값을 조건부로 latent 문서를 제공한다. Seq2seq 모델(BART)는 latent 문서들과 입력을 조건부로 출력 결과를 생성한다.
이때 Latent 문서는 top-k개의 문서들의 근사화로 marginalize 시킨다.
본 논문에서는 per-output basis marginalize(문서 하나가 모든 토큰에 영향을 미치는), per-token basis marginalize(각 토큰들마다 영향을 미치는 문서가 다른)에 대해 각각 실험한다
2. Methods
RAG는 Retriever와 Generator로 구성되어 있다.
- Retriever $p_η(z|x)$: 주어진 쿼리 $x$에 대한 분포를 반환
- Generator $p_\theta(y_i|x, z, y_{1:i-1})$ : 이전의 $i-1$ 개의 토큰들과, 입력 $x$, 문서 $z$ 에 기반하여 현재 토큰 $y_i$ 를 생성한다.
Latent 문서들의 marginalize 방법
- RAG-Sequence: 각 타겟 토큰 예측에 동일한 문서를 사용
- RAG-Token: 각 타겟 토큰 예측에 여러 문서를 사용
2.1. Models
RAG-Sequence Model

검색된 문서를 전체 시퀀스를 생성하는 데 사용하는 단일 latent variable로 처리하여, $p(y|x)$를 marginalize한다.
RAG-Token Model

매 토큰 생성 시마다 서로 다른 문서를 선택적으로 사용한다.
2.2. Retriever: DPR
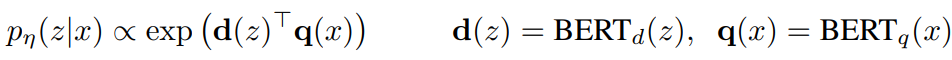
$d(z)$: BERT_base document encoder로 생성된 벡터 representation
$q(x)$: BERT_base query encoder로 생성된 벡터 representation
top-k 문서를 선택하는 계산은 sub-linear 시간 내에 계산 가능한 Maximum Inner Product Search (MIPS) 문제로써 접근한다.
→ non-parametric memory
2.3. Generator: BART
$p_{\theta}(y_i | x, z, y_{1:i-1})$ 를 위한 seq2seq 모델은 어떤 것이든 괜찮으며, 본 연구에서는 BART-large를 활용하였다. $x$와 $z$는 단순히 concatenate하였다.
→ parametric memory
2.4. Training
retriever와 generator 모두 어떤 문서가 검색되어야 하는지에 대한 직접적인 supervision 없이 jointly 하게 학습하였다.
학습 중에 document encoder를 매번 업데이트하는 것은 비용이 크기 때문에, document encoder는 고정하고 query encoder, BART generator만 업데이트하였다.
2.5. Decoding
RAG-Token
일반적인 beam-search 기법 사용
RAG-Sequence
Thorough decoding:
- beam-search 기법 적용이 어렵기 때문에, 각 문서 $z$마다 $pθ(y_i|x, z, y_{1:i−1})$로 beam-search를 해서 후보 답변 집합 $Y$를 생성한다.
- 각 후보 답변 $y$의 확률을 추정하기 위해 beam에 등장하지 않은 $y$의 문서 $z$에 대해 추가적인 forward pass를 수행한다.
- 이후 다음 generator 확률을 $p_\eta(z|x)$와 곱한 후 beam 전체에서 주변 확률을 곱한다.
Fast decoding:
긴 출력 시퀀스에서는 $|Y|$가 커짐에 따라 많은 forward pass가 필요해진다. 더 효율적인 디코딩을 위해, $p_{\theta}(y|x, z_i) ≈ 0$ 으로 근사한다.
3. Experiments
3.1. Open-domain Question Answering
질문에 대한 답변의 negative log-likelihood를 최소화 하는 방향으로 학습
3.2. Abstractive Question Answering
간단한 extractive QA를 넘어, 자유 형식의 생성으로 답변한다.
3.3. Jeopardy Question Generation
답변에 따라 질문을 생성해야 하는 Open Domain Question Generation의 성능도 실험한다.
3.4. Fact Varification
자연어 주장이 위키피디아로 뒷받침되는지, 혹은 결정할 만큼의 정보를 가지고 있는지를 분류하는 task이다.
4. Results
4.1. Open-domain Questino Answering
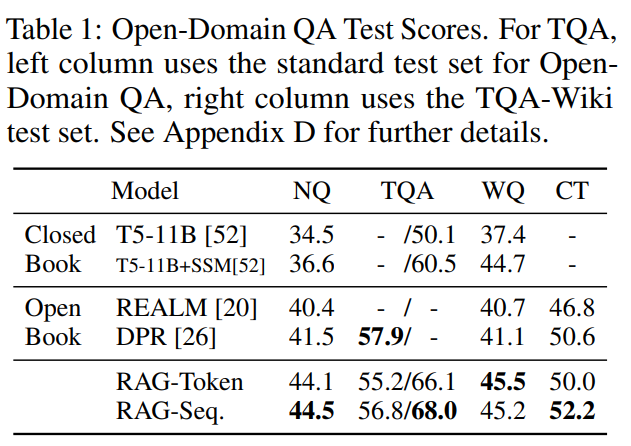
RAG는 REALM과 달리 값비싼 pre-training 기법 없이도 좋은 성능을 달성하였으며, parametric memory 기반인 T5도 능가하였다.
extractive 방식에 비해 생성 방식의 장점으로는 문서에 정답이 명시적으로 존재하지 않고 단서만 있는 경우에도 정확한 정답을 생성할 수 있다는 것이다.
4.2. Abstractive Question Answering

RAG가 gold passage가 없는 불리한 환경에서도 BART를 능가하였다.
4.3. Jeopardy Qeustion Generation

Figure2를 보면 generator가 parametric 지식 만으로도 제목을 완성하기에 충분하다는 것을 알 수 있는데, 이를 통해 non-parametric 메모리는 내부적으로 저장한 지식(parametric memory)를 이끌어내는 역할을 한다고 말할 수 있다.
4.4. Fact Verification
3-way 분류에서 RAG는 복잡한 도메인 specific 아키텍처 없이도 SOTA보다 4.3% 앞섰으며, 2-way 분류에서는 SOTA보다 2.7% 앞섰다.
4.5. Additioanl Results
Generation Diversity

RAG-Sequence와 RAG-Token 방식은 생성한 토큰의 다양성이 더 높았다.
Retrieval Ablations

RAG의 핵심적인 특징은 관련 정보 검색을 학습하는 것이다.
FEVER task에서, 검색을 BM25로 바꾼 것이 성능이 가장 좋았는데, 이는 FEVER가 entity 중심적인 task이기 때문에 단어 중첩을 고려하는 BM25의 성능이 좋게 나타난 것으로 보인다.
나머지 task에서는 학습 가능한 retriever의 성능이 더 좋았다.
Index hot-swapping
non-parametric memory의 강점은 test 때도 지식을 업데이트할 수 있다는 점이다.
Effect of Retrieving more documents

RAG 모델을 학습할 때 문서 top-k를 5, 10으로 각각 실험해보았는데 큰 차이를 발견하지는 못하였다. top-k를 늘릴수록 성능이 점진적으로 증가하지만 10에서 정점을 찍는다.
'NLP' 카테고리의 다른 글
| [Paper Review] RAGAS: Automated Evaluation of Retrieval Augmented Generation (0) | 2025.01.15 |
|---|---|
| [Paper Review] When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories 리뷰 (Adaptive RAG) (3) | 2024.12.11 |
| [Paper Review] REALM: Retrieval-Augmented Language Model Pre-Training 리뷰 (1) | 2024.12.02 |
| Llama2 초간단 요약 (0) | 2023.07.23 |
| NLP 트렌드의 흐름 간단 요약 (0) | 2023.06.23 |